
Vector databases, also known as vector stores, are specialized database systems designed to handle complex, high-dimensional data. They convert structured and unstructured information into vector embeddings—numerical representations that capture the essence of each data point. These databases excel at storing, indexing, and retrieving these vector embeddings quickly and efficiently.
Key features of vector databases include:
- Similarity search
- CRUD (Create, Read, Update, Delete) operations
- Metadata filtering
- Horizontal scaling
- Serverless capabilities
Why do vector databases matter? They are transforming various industries, particularly those dealing with large amounts of unstructured data and requiring rapid, context-aware information retrieval
In e-commerce, for example, vector databases are revolutionizing personalized product recommendations. They represent products and customer preferences as points in a multidimensional space, allowing for swift identification of patterns in customer behavior. This enables almost prescient suggestions as if the system is reading the customer’s mind.
As AI becomes more prevalent across industries, the importance of vector databases continues to grow. They power innovations that create more engaging and insightful experiences in various fields, from e-commerce and content recommendation to scientific research and financial analysis.
In conclusion, vector databases matter because they provide a powerful tool for handling the increasing complexity and volume of data in our digital world, enabling more intelligent, efficient, and personalized data-driven solutions across numerous sectors.
What are the differences between vector databases vs traditional databases?

Traditional databases store standard data types like strings and numbers in rows and columns, using indexes or key-value pairs for queries that look for exact matches. They are optimized for vertical scalability with structured data (relational databases) or horizontal scalability for unstructured data (NoSQL databases).
In contrast, vector databases introduce a new data type: vectors. These databases are optimized for storing, retrieving, and conducting nearest-neighbor searches using vectors. Unlike traditional databases, which provide exact results, vector databases store data as floating-point numbers and use Approximate Nearest Neighbor (ANN) algorithms to find the most similar results to a query. This makes vector databases ideal for AI applications that require handling large volumes of high-dimensional data, offering scalability and flexibility that traditional databases cannot achieve.
What is Vector embedding?
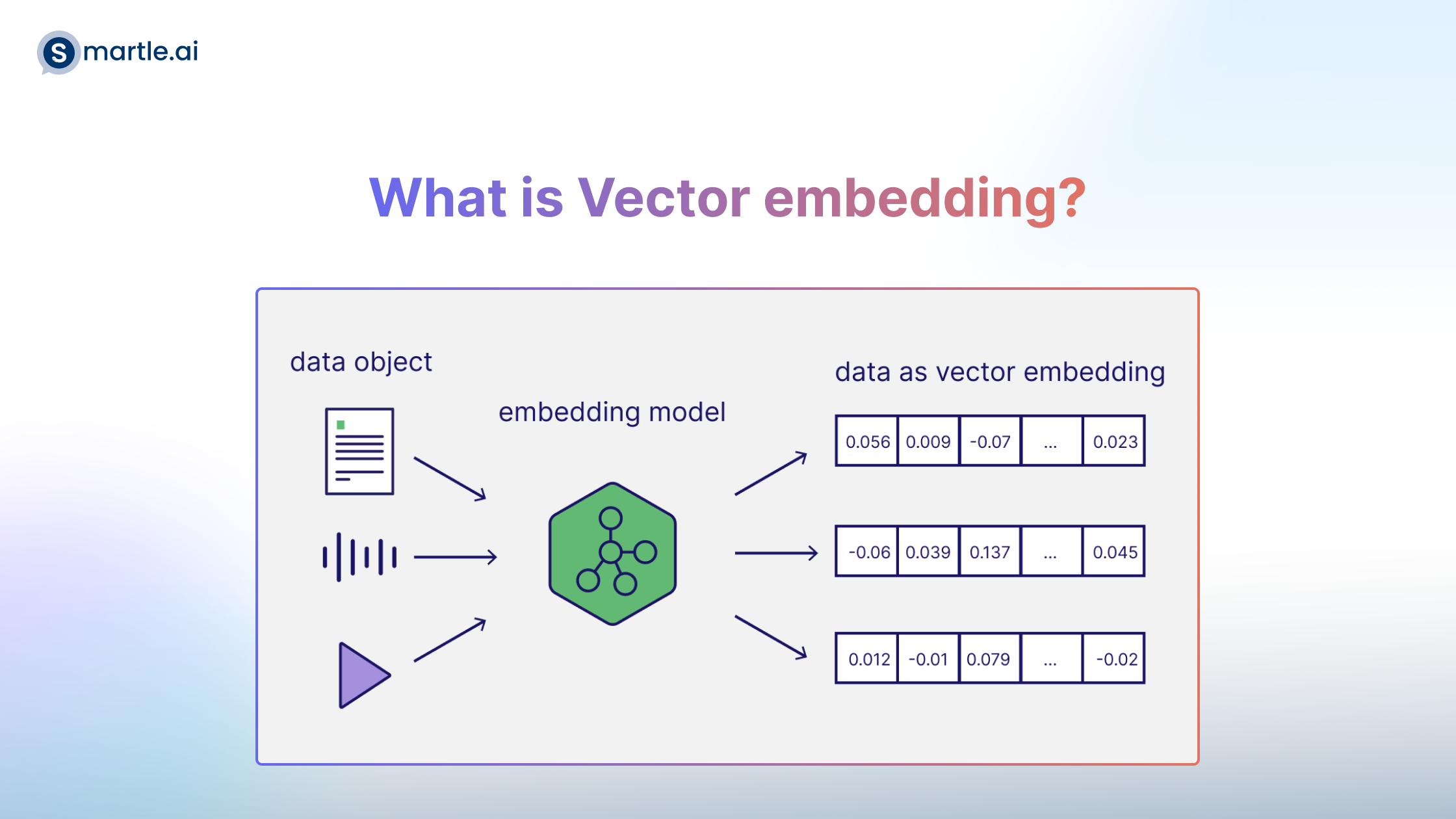
Vector embeddings are a numerical representation of a subject, word, image, or any other piece of data. Vector embeddings — also known as embeddings — are generated by large language models and other AI models.
The distance between each vector embedding is what enables a vector database, or a vector search engine, to determine the similarity between vectors.
There are 3 steps to how a vector database works:
- Vectorization: Vectorization is the foundational step in the operation of a vector database. It involves transforming various types of input data, such as text, images, or audio, into numerical vectors. Vectorization analyzes the input and generates high-dimensional vectors, typically containing hundreds or thousands of elements. Each vector serves as a dense, mathematical representation of the original data, capturing its semantic meaning and key features in a format that computers can efficiently process and compare.
- Indexing: Once the data has been vectorized, the indexing step organizes these vectors for efficient retrieval. This process is crucial for enabling fast similarity searches across millions of vectors. Vector databases employ specialized indexing algorithms, often based on Approximate Nearest Neighbor (ANN) search techniques.These algorithms create a complex data structure that clusters similar vectors together and establishes navigable paths between them. The resulting index dramatically reduces the search space, allowing for rapid identification of similar vectors without the need to exhaustively compare against every item in the database.
- Querying: The querying step is where the vector database demonstrates its power in finding similar items. When a user submits a search query, it first undergoes the same vectorization process as the stored data. The resulting query vector is then compared against the indexed vectors in the database. Leveraging the efficient index structure, the system quickly narrows down to the most promising candidates without a full linear search. It then calculates similarity scores between the query vector and these candidates, typically using metrics like cosine similarity or Euclidean distance. The system returns the original data items corresponding to the vectors with the highest similarity scores, effectively providing the most relevant results to the user’s query in a fraction of the time it would take to search through unstructured data.
What’s the difference between a vector index and a vector database?
Standalone vector indices like FAISS(Facebook AI Similarity Search) can significantly improve the search and retrieval of vector embeddings, but they lack capabilities that exist in any database. Vector databases, on the other hand, are purpose-built to manage vector embeddings, providing several advantages over using standalone vector indices:
- Data management: Vector databases offer well-known and easy-to-use features for data storage, like inserting, deleting, and updating data. This makes managing and maintaining vector data easier than using a standalone vector index like FAISS, which requires additional work to integrate with a storage solution.
- Metadata storage and filtering: Vector databases can store metadata associated with each vector entry. Users can then query the database using additional metadata filters for finer-grained queries.
- Scalability: Vector databases are designed to scale with growing data volumes and user demands, providing better support for distributed and parallel processing. Standalone vector indices may require custom solutions to achieve similar levels of scalability (such as deploying and managing them on Kubernetes clusters or other similar systems). Modern vector databases also use serverless architectures to optimize cost at scale.
- Real-time updates: Vector databases often support real-time data updates, allowing for dynamic changes to the data to keep results fresh, whereas standalone vector indexes may require a full re-indexing process to incorporate new data, which can be time-consuming and computationally expensive. Advanced vector databases can use performance upgrades available via index rebuilds while maintaining freshness.
- Backups and collections: Vector databases handle the routine operation of backing up all the data stored in the database. Pinecone also allows users to selectively choose specific indexes that can be backed up in the form of “collections,” which store the data in that index for later use.
- Ecosystem integration: Vector databases can more easily integrate with other components of a data processing ecosystem, such as ETL pipelines (like Spark), analytics tools (like Tableau and Segment), and visualization platforms (like Grafana) – streamlining the data management workflow. It also enables easy integration with other AI related tooling like LangChain, LlamaIndex, Cohere, and many others..
- Data security and access control: Vector databases typically offer built-in data security features and access control mechanisms to protect sensitive information, which may not be available in standalone vector index solutions. Multitenancy through namespaces allows users to partition their indexes fully and even create fully isolated partitions within their own index.
In short, a vector database provides a superior solution for handling vector embeddings by addressing the limitations of standalone vector indices, such as scalability challenges, cumbersome integration processes, and the absence of real-time updates and built-in security measures, ensuring a more effective and streamlined data management experience.
How are vector databases used?
- Similarity and semantic searches: Vector databases allow applications to connect pertinent items together. Vectors that are clustered together are similar and likely relevant to each other. This can help users search for relevant information (e.g. an image search), but it also helps applications:
- Recommend similar products
- Suggest songs, movies, or shows
- Suggest images or video
- Machine learning and deep learning: The ability to connect relevant items of information makes it possible to construct machine learning (and deep learning) models that can do complex cognitive tasks.
- Large language models (LLMs) and generative AI: LLMs, like that on which ChatGPT and Bard are built, rely on the contextual analysis of text made possible by vector databases. By associating words, sentences, and ideas with each other, LLMs can understand natural human language and even generate text.
Best Vector Databases in 2024

1. Chroma
Chroma, an open-source vector database, offers different storage options for developing large language models. It supports standalone deployments with DuckDB and scalable deployments with ClickHouse. It provides SDKs for Python and JavaScript/TypeScript, making it user-friendly.
Key features:
- Open-source database
- SDKs for Python and JavaScript/TypeScript
- Integration with ClickHouse
- Automatic data saving and reloading
- Multiple storage options
2. Pinecone
Pinecone is a cloud-native database designed for applications involving large language models. It offers a simple API for Python, JavaScript/TypeScript, and REST to facilitate integration with various programming languages and frameworks.
Key features:
- Fully managed service
- Dense and sparse vector embedding
- Rich metadata support
- Integration with popular AI and machine learning tools
- Real-time data ingestion
3. Weaviate
Weaviate is an open-source vector database that stores both vectors and objects. This allows developers to handle structured and unstructured data in one place, making it unique from other databases.
Key features:
- Low-latency vector database
- Real-time search
- Semantic search, question-answer extraction, classification, customizable models (PyTorch/TensorFlow/Keras)
- Stores both objects and vectors
- Cloud-native database
- Accessible through GraphQL, REST, and various client-side programming languages
4. Qdrant
Qdrant’s API allows easy integration with your preferred programming language. You can build your own code for API interaction or use pre-built libraries for simpler implementation. This cloud-native platform uses the HNSW algorithm for accurate nearest-neighbour search, ensuring fast and reliable results.
Key features:
- Easy-to-use API
- Ready-made client for Python
- Additional payload support
- Supports a variety of data types, including strings, numerics, geo-locations, and more
- Cloud-native and scalable
Conclusion
Vector databases are revolutionizing AI applications across the board. From powering AI search engines on websites and enabling Retrieval-Augmented Generation (RAG) use cases to providing permanent memory capabilities, vector databases are key to making AI smarter and more intuitive. Their role in enhancing NLP, computer vision, and LLMs is undeniable, allowing developers to build customized, scalable solutions that traditional databases simply can’t match. As AI continues to evolve, vector databases will be indispensable in bridging the gap between humans and machines, creating more interactive and responsive technology experiences.


